Software projects face a unique set of challenges when it comes to scope estimating and this is especially true for new software developments. Research has found that poor cost and schedule estimates are much more detrimental to software projects than any other problem. Typically, estimates are based on historical project information and/or expert opinion, which can be more of an art than a science. The author, William Roetzheim, suggests a more systematic approach to planning estimates for new software projects using research-based techniques.
Based on his experience with software projects, Roetzheim suggests companies take an approach similar to that found in the PMBOK when it comes to life cycle cost estimating accuracies. Initial estimations should be within +/- 50% of the actual cost and the budget should continue to be refined as the project’s requirements are more fully understood.
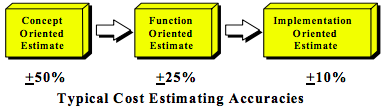
The first step to estimate scope is to determine metric used as a measure of scope. In software there are numerous options, but the most common is the number of source lines of code (SLOC), which is the number lines of code written by humans and is usually given as thousands of SLOC (KSLOC).
To determine the number SLOC, you can use one of two options: the direct estimating approach and the function points (FPs) with backfiring approach. Using the direct estimating approach, you break the project down into modules and use multiple expert opinions to estimate the number SLOC’s per module. This is called a Program Evaluating and Reviewing Technique (PERT) calculation and is done by obtaining optimistic, pessimistic, and most likely values. The most likely value is weighted times 4 and the mean and standard deviation are calculated and used to create an estimate with a high level of accuracy.
The FPs with backfiring approach uses the estimate of the number of logical internal tables and external inputs, outputs, interface files, and queries to estimate the number of ways the program must interact with the users. Then you multiply the raw data by its FP conversation factor to fund the number of FPs.

Then using backfiring you convert the FPs to SLOC using the function point for the applicable language.
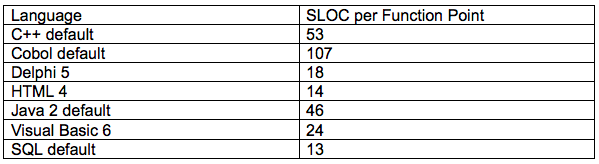
Once you have estimated the number of KSLOC, you take that number and multiply it by the effort required per KSLOC to find the estimate for the project. Researchers have come up with estimates for the effort required per KSLOC based upon different project types. For smaller projects, you would multiply the number of KSLOC by the productivity factor of the applicable project time to find the number of person-months the project requires.
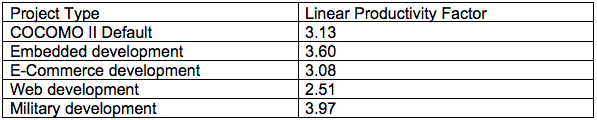
Since research has found that large projects tend to be less productive due to increased time spent communicating and coordinating, you must apply a penalty factor to the above calculation for larger projects. The calculation for the larger project would then = Productivity Factor * KSLOC^Penalty Factor.
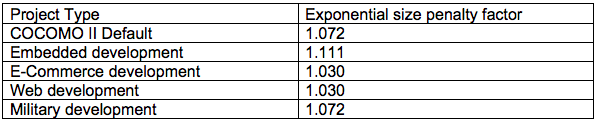
The author argues that the calculation above will deliver a reliable person-months estimate feeds into the project’s schedule and budget and that it should continue to be managed as the project moves forward in its lifecycle.
While the author’s presents his methods for estimating scope for a software project, he does make any recommendations on how to utilize them. If your company conducts software projects, does it use SLOC when estimating? Is there a specific process used to calculate time requirements and how does it compare to the process suggested by the author?
Roetzheim, W. (2005) Estimating and Managing Project Scope for New Development. Journal of Defense Software Engineering, 4-7.
Thanks for taking the time to write this up. I had a question I thought would be worth exploring for yourself or anyone else that stumbled upon this…
The question is rather broad and can be explored from a multitude of angles so hopefully, someone else pulls the conversation along after my thoughts:
How do these formula’s account for the human element?
What if my team has 4 embedded engineers, working on a massively complex high volume code base application, and one of them become less motivated. Maybe they get married and decide to live without electronics because thats what their wife does and it’s true love, maybe this engineer becomes interested in, oh, I don’t know, wood working or bonzai tree growing! Jokes aside, it seems a rather modern approach to solve a problem by working out a standard deviation, deriving a tangent, and projecting from there. These systemic problem solving tools build in a strong foundation and can usually be held true, but what they seem to often ignore, or mathematically mitigate, is the extrema conditions that lie on the tail ends of the bell curve. Those small outcomes of success, you know the moonshots that are well past your Six-Sigma, hold my fascination.
I read a quote somewhat recently that has a strong application here, “It (life) doesn’t work as a formula, you have to mean it.”. How does this formula account for the externalities of the real world. When I see formulas designed such as this one, my inner skeptic asks what are the range of tolerance this has, how is it designed to accommodate such a complex factor, does the model it presents provide for consideration of unrealistic and yet still plausible factors. In an perfect model world everything works, all the time, but as we all know well, that’s not reality. Formulas and expressions such as this authors are built to solve problems and get us a best guess, I don’t feel they should be trumpeted as the best answer without remembering that people have the unique ability to make a decision, and in such shock the system.
Thank you for your response, Sean. I think you bring up a very important point, one that really cuts to the heart of the ‘science’ of project management. As a PM, you are managing a budget, schedule, and resources, but essentially you are managing people. And as you said, there is no formula that can fully encompass the human variable. Unfortunately, I think that this just has to be accepted and then mitigated. I think the most important way to help account for the human element is a skilled project manager. If an employee is checking out and not meeting deadlines, a good project manager will catch it and work to correct it before it becomes a major problem.
The author suggests some good ways to help account for the human element when estimating a schedule. First, like the PMBOK he suggests doing multiple rounds of schedule estimation the further and further you get into the project. Each round should be more accurate as there are fewer unknowns. Second, he suggests using the PERT method of estimating, which can help account for the variability of LOC outputs per person and per day. Third, he offers a way to use his formulas with function points instead of LOC. Not all lines of code are created the same, and function points help account for the man hours required to create differing complexities of code. I think all of these together can best mitigate the human variable that cannot be totally eliminated.